
pysparkling is a pure Python implementation of Apache Spark's RDD interface.
It means you can do pip install pysparkling and start running Spark code in
Python. Its main use is in low latency applications where Spark operations
are applied to small datasets. However, pysparkling also supports the
parallelization of map operations through multiprocessing, ipcluster and
futures.concurrent. This feature is still in development, but this post
explores what is already possible. Bottlenecks that were found while
writing this post are now included in version 0.3.10.
Benchmark
I wanted to measure a CPU-bound benchmark to see the overhead of object serialization in comparison to actual computations. The benchmark function is a Monte Carlo simulation to calculate the number \(\pi\). It generates two uniformly distributed random numbers x and y each between 0 and 1 and checks whether \(x^2 + y^2 < 1\). The fraction of tries that satisfy this condition approximates \(\pi\)/4.
To understand the process better, I instrumented the job execution with timers.
The cumulative time spent in parts like data deserialization on the worker
nodes and a few more are aggregated in the Context._stats variable.
A few problems became apparent:
- The function that is applied in a map operation is the same for all partitions of the dataset. In the previous implementation, this function was serialized separately for every chunk of the data.
- Through a nested dependency, all partitions of the data were sent to all the workers. Now only the partition that a given worker processes is sent to it.
- Another slowdown was that core pysparkling functions were not pickle-able.
That is not a problem for
cloudpickle, but serializing and deserializing non-pickle-able functions takes longer. Themap()andwholeTextFiles()methods have pickle-able helpers now.
Results
The test was run on a 4-core Intel i5 processor and this is the result:
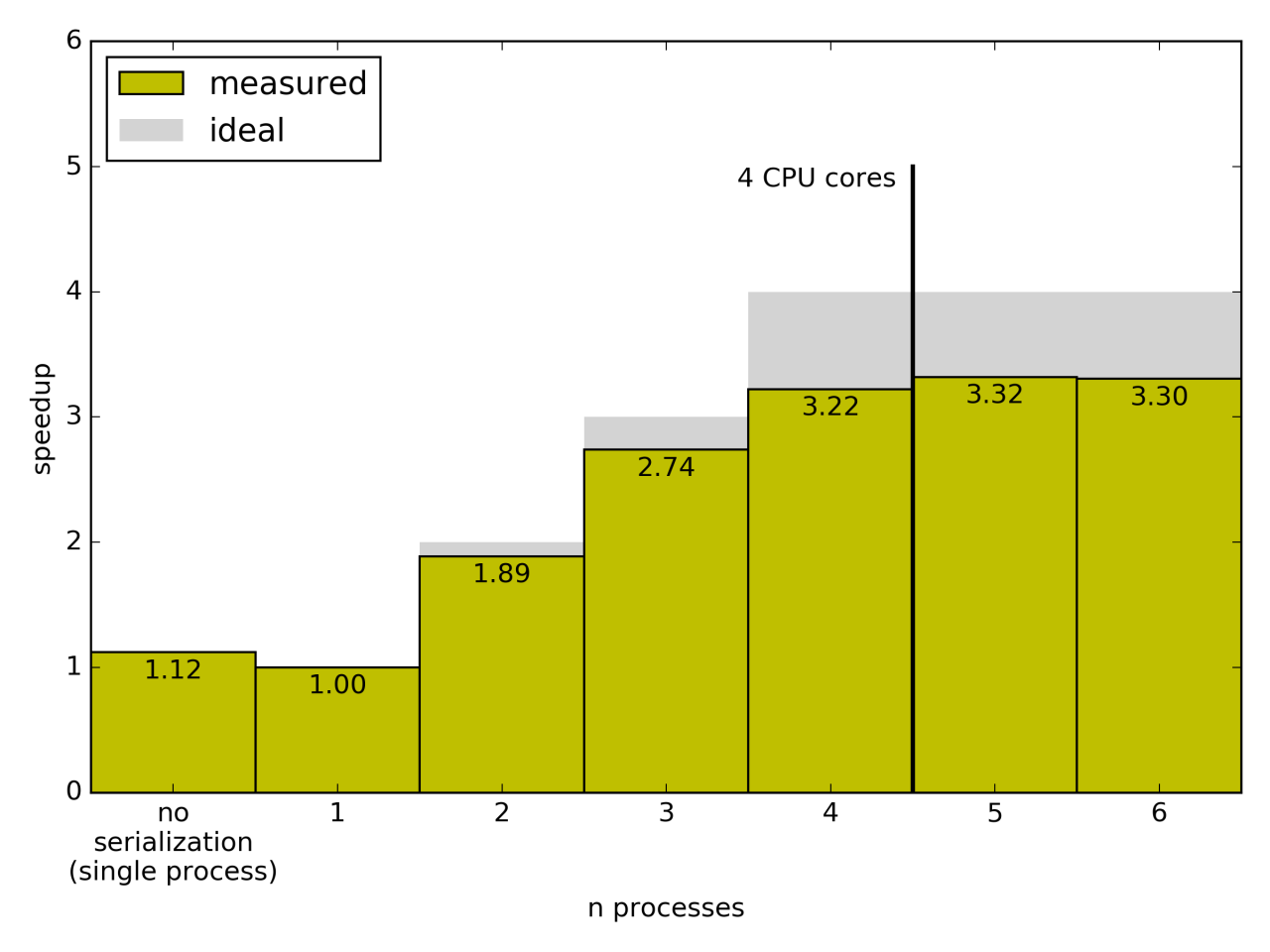
Achieving a 3x improvement with four cores is good in real world benchmarks.
The new Context._stats variable gives more insight into where time is
actually spent. The numbers below are normalized with respect to the time
spent in the execution of the map function. The results for this CPU bound
benchmark with four processes are:
- map exec: 100.0%
- driver deserialize data: 0.0%
- map cache init: 0.2%
- map deserialize data: 0.0%
- map deserialize function: 2.1%
Most of the time is spent in the actual map where it should be. The time it
takes to deserialize the map function is 2.1% of the time it takes to execute
it. The benchmark itself is run as a unit test in
tests/test_multiprocessing.py
and the plots can be recreated with ipython tests/multiprocessing_performance_plot.py.
The test was also run on a 4-core Intel i7 processor with Hyperthreading. You can see that the performance is slightly better than with the i5, but that the doubled threads do not double the performance.
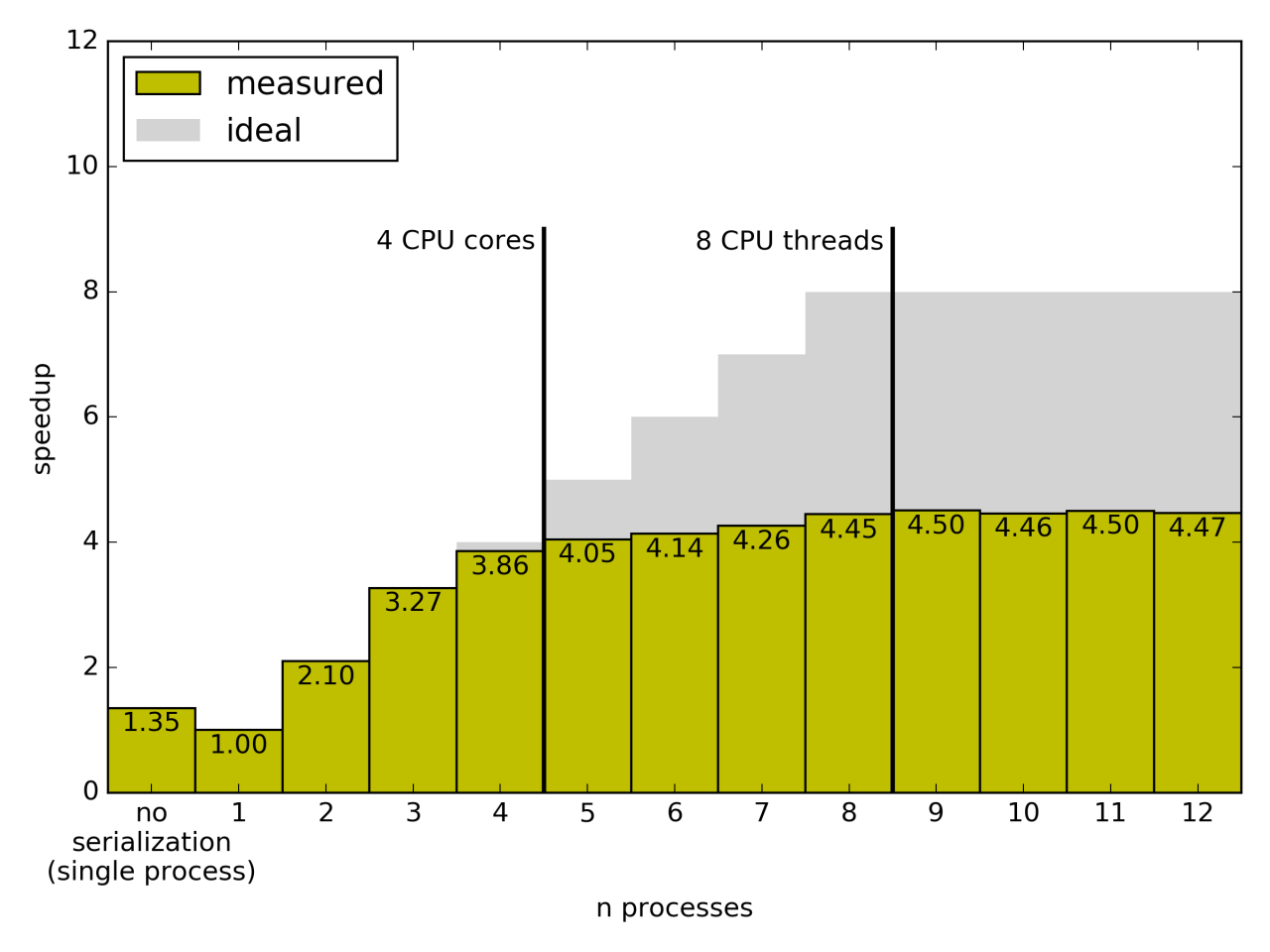
As a first pass at multiprocessing with pysparkling, this is a good result.
Please check out the project on Github,
install it with pip install pysparkling and send feedback.