
Word2vec is an interesting approach to convert a word into a feature vector (original C code by Mikolov et al). One of the observations in the original paper was that words with similar meaning have a smaller cosine distance than dissimilar words. Here is a histogram of the pairwise cosine distances of about 500 media topics (derived from IPTC news codes):
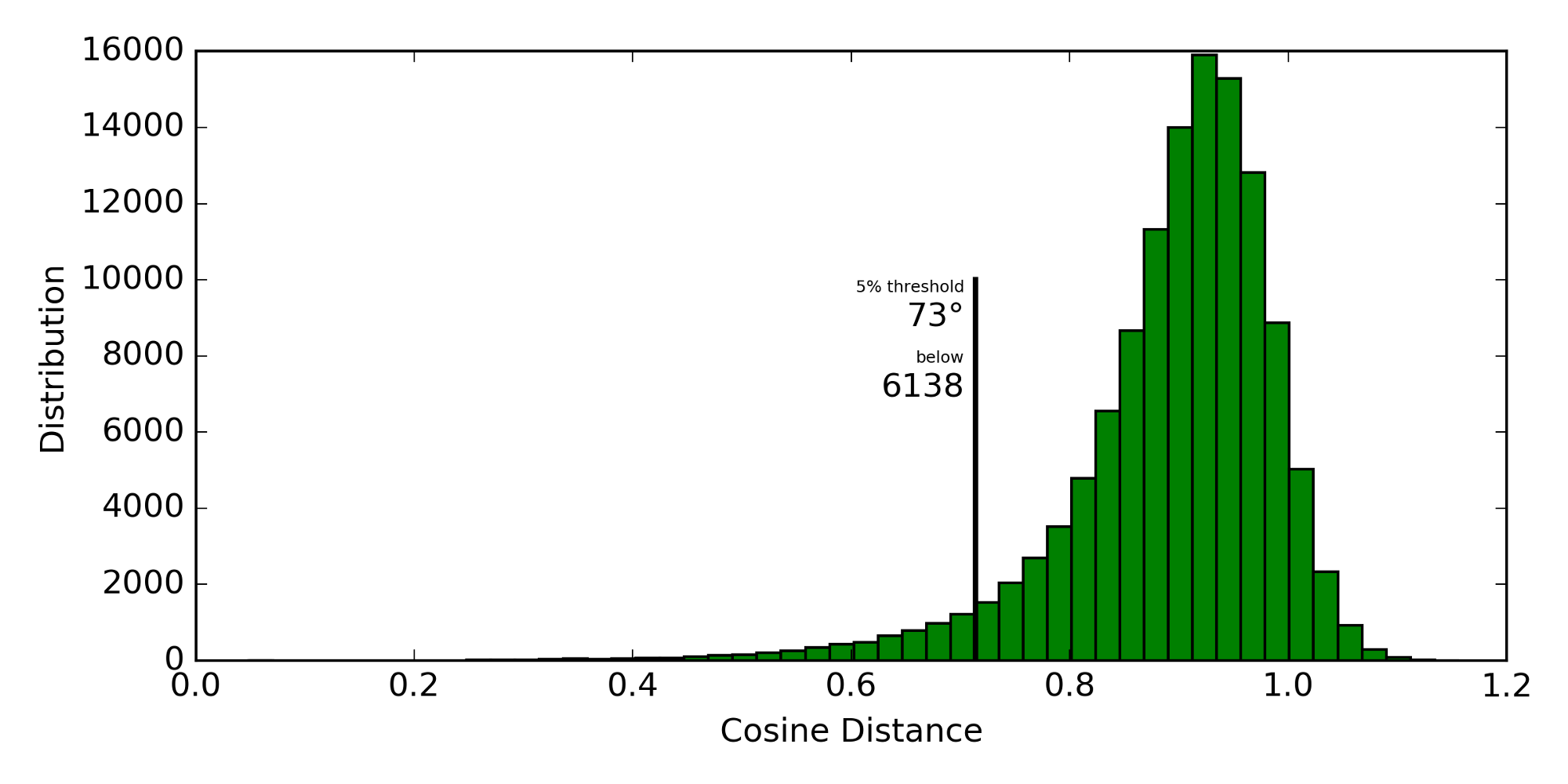
Cosine distance is defined as 1 - cos(vector1, vector2). Most of the vector
pairs only have slightly smaller angles than 90° which makes sense as more
topics are unrelated to each other than related. The closest 5% of vector
pairs are still separated by angles up to 73°. The smallest angular separation
is 18° between breaststroke and backstroke and the second smallest
is 27° between triple_jump and pole_vault.
To visualize these topics below, the 300-dimensional word vectors are embedded in two dimensions using t-SNE. Edges between the topics with the smallest 5% in cosine distance in the original space are drawn in orange.

Similar topics are indeed close together. However, one could argue that imports is the opposite of exports and therefore should not be close together; but they are (at the bottom). Similarly, employment is close to unemployment. This is not how a person would think about “similarity” in this context, but it makes sense given the skip-gram training of the word vectors: a neural network tries to predict a word (here a topic) given a window of surrounding words. These topics would indeed appear in news articles with similar words surrounding them. It is important to keep this subtlety in mind when building tools on top of word2vec.
Using word2vec on Databricks
Spark and MLlib come with a built-in implementation of word2vec. However, we
also want to apply word2vec in stand-alone Python and therefore chose the
gensim implementation.
We use Databricks to process a large number of documents (not for training
word2vec, but to apply word2vec). We create a “Mapper Tool” that can convert
text to word vectors that is distributed in a Python egg. This tool reads
in previously created word vectors from a compressed binary file that is larger
than 1GB which takes about a minute.
There are two ingredients that we need: a large binary input file available at all worker nodes and a way to cache the word vectors in memory across map operations.
dbutils.fs.mount('s3n://your_bucket/some_folder', '/mnt/some_folder')
The default scheme is dbfs:/, not file:/, which means that this S3 folder
is now available in dbfs. dbutils can copy data from dbfs to the local
file system, but only on the driver. On worker instances, dbutils is not
available. However, dbfs is mounted using FUSE at file:/dbfs
(Databricks Forum post)
and we can use the local file path /dbfs/mnt/some_folder/word2vec_file.bin.gz
on the driver and the workers.
Mapper Tool
The tool is a wrapper around the word2vec implementation in the Python package
gensim,
gensim.models.Word2Vec. We want an in-memory cache that is persistent across
map operations. Python class variables are not serialized when serializing an
instance of a class and therefore we can use it as a process-wide cache.
from gensim.models.word2vec import Word2Vec
class Tool(object):
cache = {}
def __init__(self, filename):
self.fn = filename
@property
def word2vec(self):
if self.fn not in Tool.cache:
Tool.cache[self.fn] = \
Word2Vec.load_word2vec_format(self.fn, binary=True)
return Tool.cache[self.fn]
def map(self, word):
if word not in self.word2vec:
return None
return self.word2vec[word]
You can use this tool on the driver or in a map function that gets shipped to
the workers. The call to load_word2vec_format() is expensive, but in this
design only executed once in each process.
Example application:
filename = '/dbfs/mnt/some_folder/word2vec_file.bin.gz'
sentence = ['Some', 'sentence', 'as', 'a', 'test']
sc.parallelize(sentence, 2).map(Tool(filename).map).collect()
There are of course other ways to accomplish this, but I wanted to share the method that works well for us.
Summary
This post gave an introduction to word2vec and showed how to distribute a large input file to worker nodes on Databricks. It also showed how to create a Mapper Tool that can cache input data across map jobs in memory.
During this work, I submitted two pull requests to gensim
#545 and
#555 which are merged into the
master branch. With the next release, load_word2vec_format() will be faster.